假如SQL Server数据库中现在有Book表如下
CREATE TABLE [dbo].[Book]( [ID] [int] IDENTITY(1,1) NOT NULL, [BookName] [nvarchar](50) NULL, [BookDescription] [nvarchar](50) NULL, [ISBN] [nvarchar](20) NULL, [CreateTime] [datetime] NULL, CONSTRAINT [PK_Book] PRIMARY KEY CLUSTERED ( [ID] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]) ON [PRIMARY]GOALTER TABLE [dbo].[Book] ADD CONSTRAINT [DF_Book_CreateTime] DEFAULT (getdate()) FOR [CreateTime]
有如下数据:
SET IDENTITY_INSERT [dbo].[Book] ON GOINSERT [dbo].[Book] ([ID], [BookName], [BookDescription], [ISBN], [CreateTime]) VALUES (1, N'Chinese', N'This is a very good Chinese book', N'0001', CAST(N'2018-10-17T15:25:18.450' AS DateTime))GOINSERT [dbo].[Book] ([ID], [BookName], [BookDescription], [ISBN], [CreateTime]) VALUES (2, N'English', N'English', N'0002', CAST(N'2018-10-17T15:25:18.457' AS DateTime))GOINSERT [dbo].[Book] ([ID], [BookName], [BookDescription], [ISBN], [CreateTime]) VALUES (3, N'Japanese', N'Japanese', N'0003', CAST(N'2018-10-17T15:25:18.473' AS DateTime))GOINSERT [dbo].[Book] ([ID], [BookName], [BookDescription], [ISBN], [CreateTime]) VALUES (4, N'Russian', N'Russian', N'0004', CAST(N'2018-10-17T15:25:18.483' AS DateTime))GOINSERT [dbo].[Book] ([ID], [BookName], [BookDescription], [ISBN], [CreateTime]) VALUES (5, N'Italian', N'Italian', N'0005', CAST(N'2018-10-17T15:25:18.493' AS DateTime))GOSET IDENTITY_INSERT [dbo].[Book] OFF
我们使用SELECT语句查询该表,如下所示:
SELECT *FROM [dbo].[Book]
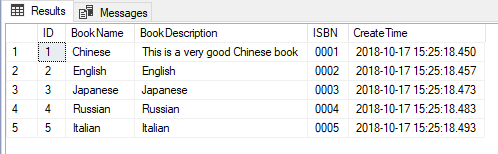
现在设想一个问题,我们如何根据[BookName]和[BookDescription]两列数据的联合值来对结果进行排序呢?
我想很多人都会想到用子查询,如下所示:
SELECT [ID],[BookName],[BookDescription],[ISBN],[CreateTime]FROM( SELECT [ID],[BookName],[BookDescription],[ISBN],[CreateTime],[BookName]+N'#'+[BookDescription] AS [Combine] FROM [dbo].[Book]) AS TORDER BY [Combine]
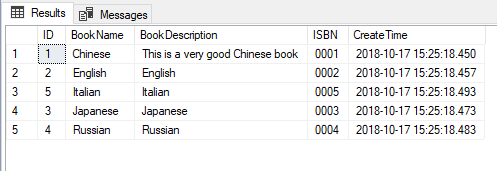
像上面这样用子查询的确没有问题,但是你知道吗,我们是可以直接在ORDER BY语句中写表达式的,如下所示:
SELECT *FROM [dbo].[Book]ORDER BY [BookName]+N'#'+[BookDescription]
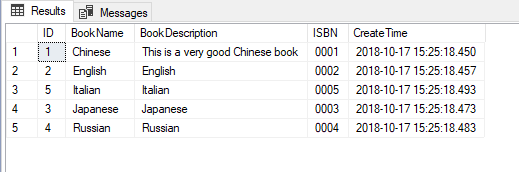
结果和用子查询完全一样
我们也可以在ORDER BY中使用多个表达式和列来对结果进行排序,甚至我们可以根据一个子查询来对结果进行排序,如下所示:
SELECT *FROM [dbo].[Book]ORDER BY [BookName]+N'#'+[BookDescription] ASC, (SELECT TOP 1 R_BOOK.[ISBN] FROM [dbo].[Book] AS R_BOOK WHERE R_BOOK.[BookName]=[BookName]) DESC, --这里的子查询只能返回一行和一列数据,否则SQL Server会报错 [CreateTime] ASC
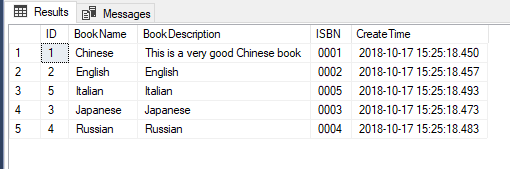
但是ORDER BY后面不能是常量,比如下面这样我们在ORDER BY后面跟一个字符串常量是不行的:
SELECT *FROM [dbo].[Book]ORDER BY N'Constant'
执行该语句会报错:
Msg 408, Level 16, State 1, Line 3A constant expression was encountered in the ORDER BY list, position 1.